
LinkedHashMap继承了HashMap,其行为和HashMap类似,只是在内部多维护了一个元素结点的双向链表。官方文档描述如下:
Hash table and linked list implementation of the Map interface, with predictable iteration order. This implementation differs from HashMap in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order). Note that insertion order is not affected if a key is re-inserted into the map. (A key k is reinserted into a map m if m.put(k, v) is invoked when m.containsKey(k) would return true immediately prior to the invocation.)
通常情况下,LinkedHashMap可以保持元素的插入顺序。另外,有一个特殊的构造方法,可以使LinkedHashMap保持元素的访问顺序,利用这个特种可以很方便的实现LRUCache。
数据结构
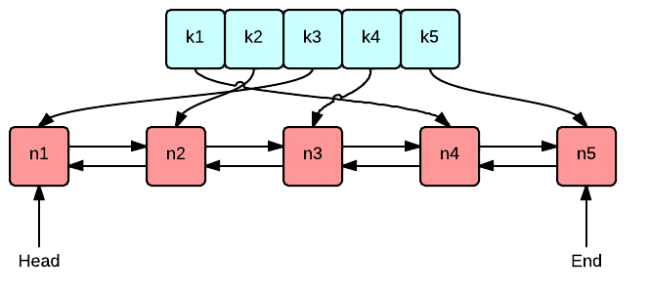
LinkedHashMap结点结构如下:
1
2
3
4
5
6
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
结点继承了HashMap的结点,并且多了before, after两个指针,用来构造双向链表。
LinkedHashMap的数据结构大概如下:
get, put, remove实现
LinkedHashMap的get,put,remove方法的实现和HashMap基本是一样的,只是多了双向链表的维护操作,并不难,不做具体的分析了。只需注意一点即可,就是新插入的结点是放在双向链表的尾部的,如果是保持accessOrder的话,每次结点访问后,也会将结点放到链表的尾部。对于双向链表的维护,主要是通过get,put,remove中的钩子方法afterNodeAccess, afterNodeInsertion, afterNodeRemoval来实现的,在HashMap中这些方法都是空的实现。大概看一下这三个方法的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
/**
* removeEldestEntry方法用来判断是否要删除链表头部的结点,默认为false。
* 我们可以重写该方法,配置accessOrder可以很容易的实现LRUCache
*/
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// accessOrder为true,会将访问的结点放到链表尾部
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
实现LRUCache
直接看代码:
1
2
3
4
5
6
7
8
9
10
11
LinkedHashMap<Integer, Integer> lruCache = new LinkedHashMap<Integer, Integer>(8, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > 5;
}
};
range(0, 100).forEach(value -> lruCache.put(value, value));
System.out.println("size: " + lruCache.size());
lruCache.keySet().forEach(System.out::println);
运行结果:
1
2
3
4
5
6
size: 5
95
96
97
98
99
这里当Map中元素超过5个,就会删除头部的元素,因此map最终只有5个最近插入的元素。
总结
如果看过HashMap的源码,LinkedHashMap并不难,除了能实现LRU外,LinkedHashMap也能产生一个Map的copy,并且保持原有的顺序。
1
2
3
4
void foo(Map m) {
Map copy = new LinkedHashMap(m);
...
}
此外,由于LinkedHashMap不是线程安全的,因此并发环境中,可以先将其包装成为同步的。
1
2
Map m = Collections.synchronizedMap(new LinkedHashMap(...));