
Protobuf是谷歌推出的跨语言,跨平台,可扩展的数据序列化机制,相比XML,JSON等序列化方式,它具有更简单,更快,更小的优点,其中体积更小的优点得益于它的encoding方式。
Protobuf 消息是一种key-value形式的结构,如下图所示
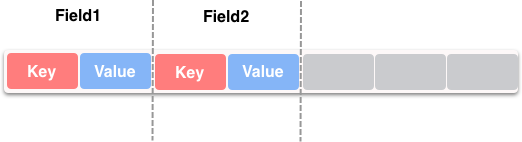
其中Key包含了field_number和wire_type,计算公式:
1
key = (field_number << 3) | wire_type
wire_type就是protobuf的编码方式,可用的wire_type和pb对应的数据类型如下:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
Base 128 Varints
Varint(可变长int类型)使用一个或者多个byte序列化int类型的方法,数字越小,需要的byte越少,类似sql的varchar。
Varint 中的每个字节(最后一个字节除外)都设置了最高有效位(msb),用来表示后续还有没有byte数据,剩下的7bits用来存储数据的二进制补码(two’s complement),因为protobuf采用小端序(little-endian byte order)编码,先读到的是低位数据,所有一个数据如果有多个byte,解析时需要反转一下顺序。
看一个例子:
1
2
3
message Test1 {
optional int32 a = 1;
}
如果将a设置为150,序列化之后的结果就是 08 96 01 ,解析时先读到一个字节08 ,二进制0000 1000,msb位是0,后续没有数据,因此第一个字节就是key,去除msb后 000 1000, 低位3bit表示wire_type,是0,所以后面的value采用varint编码,右移三位后,剩下的就是field_number,为1。
解析完key后,再去解析value,一直读到msb是0的byte停止,解析过程如下
1
2
3
4
5
96 01 = 1001 0110 0000 0001
→ 000 0001 ++ 001 0110 (丢弃msb,保留剩下的 7 bits, 并且翻转顺序)
→ 10010110
→ 128 + 16 + 4 + 2 = 150
负数
在对负数进行编码的时候,使用signed int类型(sint32 and sint64)和标准类型(int32 and int64)有一些不同,使用int32或者int64时,pb会固定使用10byte来表示负数,而使用signed int类型,会先进行ZigZag编码,再用varint方式序列化。ZigZag编码方式如下:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
ZigZag计算函数如下:
1
2
3
(n << 1) ^ (n >> 31), // n 为 sint32 时
(n << 1) ^ (n >> 63), // n 为 sint64 时
需要注意的是,这里的右移操作 (n>>31)是算数移动(arithmetic shift),如果n是正数,高位补0,如果n是负数,高位补1
Non-varint Numbers
Non-varint Numbers(fixed64, sfixed64, double, fixed32, sfixed32, float)就比较简单,只要根据wire_type类型读取固定长度的字节数就可以了。
Strings
wire type是2 (length-delimited)表示Value部分由Length和Data两部分组成,Length是采用varint编码的数字,表示Data的长度,然后就可以读取该长度的数据。实例如下:
1
2
3
message Test2 {
optional string b = 2;
}
设置 b = "testing",编码如下:
1
12 07 [74 65 73 74 69 6e 67]
[ ]中的数据是UTF8 编码的 "testing"。 key是0x12,解析如下:
1
2
3
4
0x12
→ 0001 0010 (binary representation)
→ 00010 010 (regroup bits)
→ field_number = 2, wire_type = 2
Length是07表示后续7个bytes就是数据部分,直接读取7个字节即可。
Embedded Messages
Embedded Messages的wire type也是2,因此编码方式和string类似,看下例子:
1
2
3
message Test3 {
optional Test1 c = 3;
}
设置Test1.a = 150 ,编码如下:
1
1a 03 08 96 01
08 96 01和前面例子是一样的,根据Length 03读取三个字节就得到08 96 01,对这部分数据再进行解析即可。
Repeated字段
对于repeated字段,解析时会有多个key相同的数据,这些数据不需要连续出现。
Packed Repeated Fields
packed repeated字段会将所有数据打包到一个key-value pair 中,所有数据是连续出现,打包在一起的。
1
2
3
4
message Test4 {
repeated int32 d = 4 [packed=true];
}
设置d = 3, 270, 86942,编码后:
1
2
3
4
5
22 // key (field number 4, wire type 2)
06 // payload size (6 bytes)
03 // first element (varint 3)
8E 02 // second element (varint 270)
9E A7 05 // third element (varint 86942)
只有原始数字类型(使用varint,32位或64位)的重复字段才可以声明为“packed”。
总结
protobuf在序列化方面,相比xml, json等具有更简单,更快,更小的优点,因此可以运用在数据传输(rpc),存储(缓存)等方面,不仅可以提高性能,还能节省大量存储空间,减少成本。